Projects

WEEDon't Need Humans
WEEDon't Need Humans is a machine learning project aimed at automating weed identification in agricultural fields. By classifying eight different weed species along with a ninth negative class representing non-weed images, this project aims to assist farmers in efficient weed management. Accurate weed classification enables targeted removal strategies, optimising crop yields, and minimising unnecessary herbicide usage and manual labour.
My team worked on four models for this task: a baseline Convolutional Neural Network (CNN) with three convolutional layers, a Siamese Neural Network for image comparison, and two advanced architectures, VGG16 and ResNet50. Each model was tailored for our specific dataset, with fine-tuning and adaptation to improve weed identification accuracy. This project demonstrates how machine learning can be leveraged to solve real-world agriculture challenges and promote sustainable farming practices.
Python
Image Processing
Deep Learning
PyTorch
Lecture Note Generation
The Lecture Note Generation Application is a Streamlit-based web app that leverages on Large Language Models (LLMs) to generate detailed and comprehensive lecture notes. It combines lecture recordings, raw notes taken during lectures, and additional input to produce organised notes. The app aims to help students efficiently compile their notes, providing a convenient way to review and revise lecture content using AI.
Python
LLM
Streamlit
Git

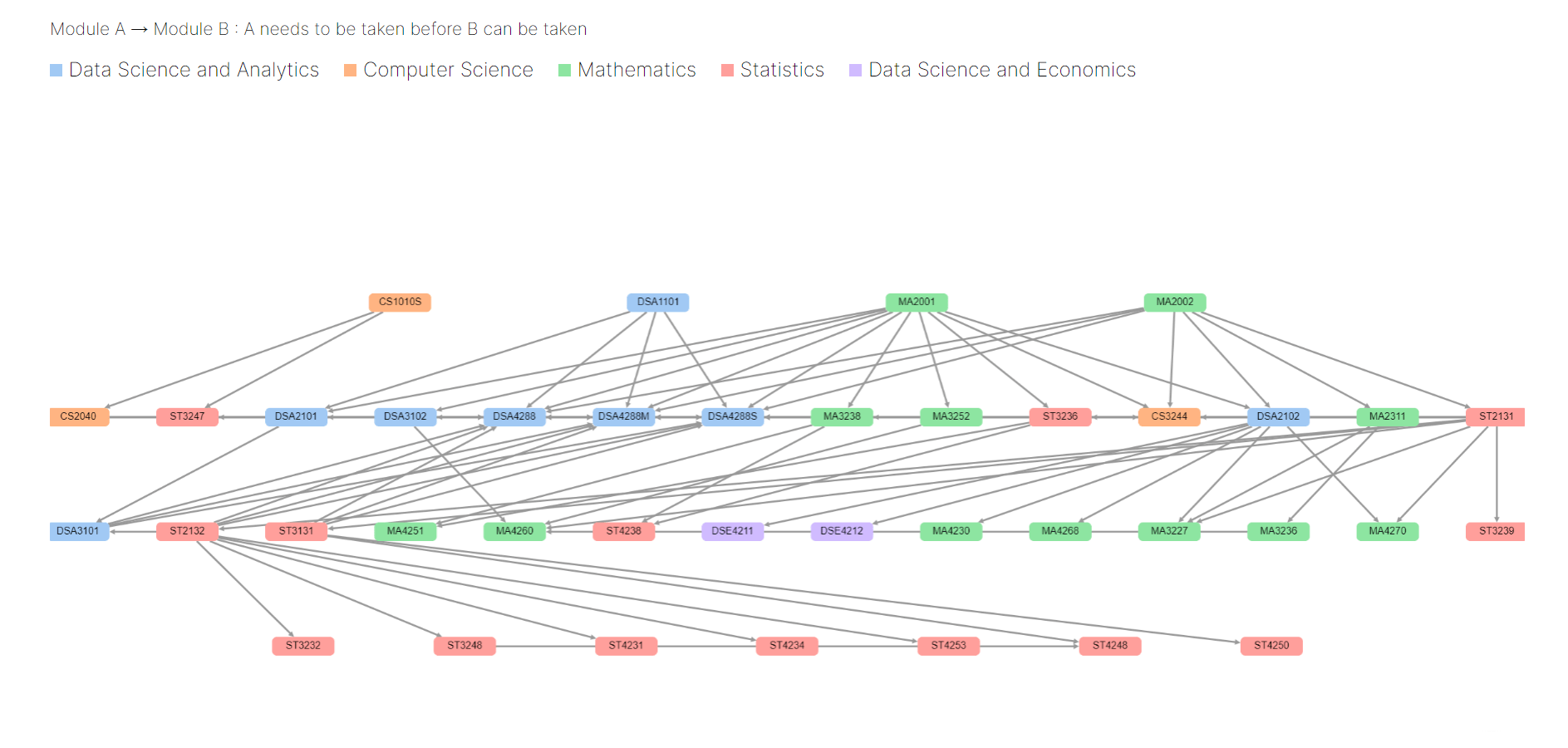

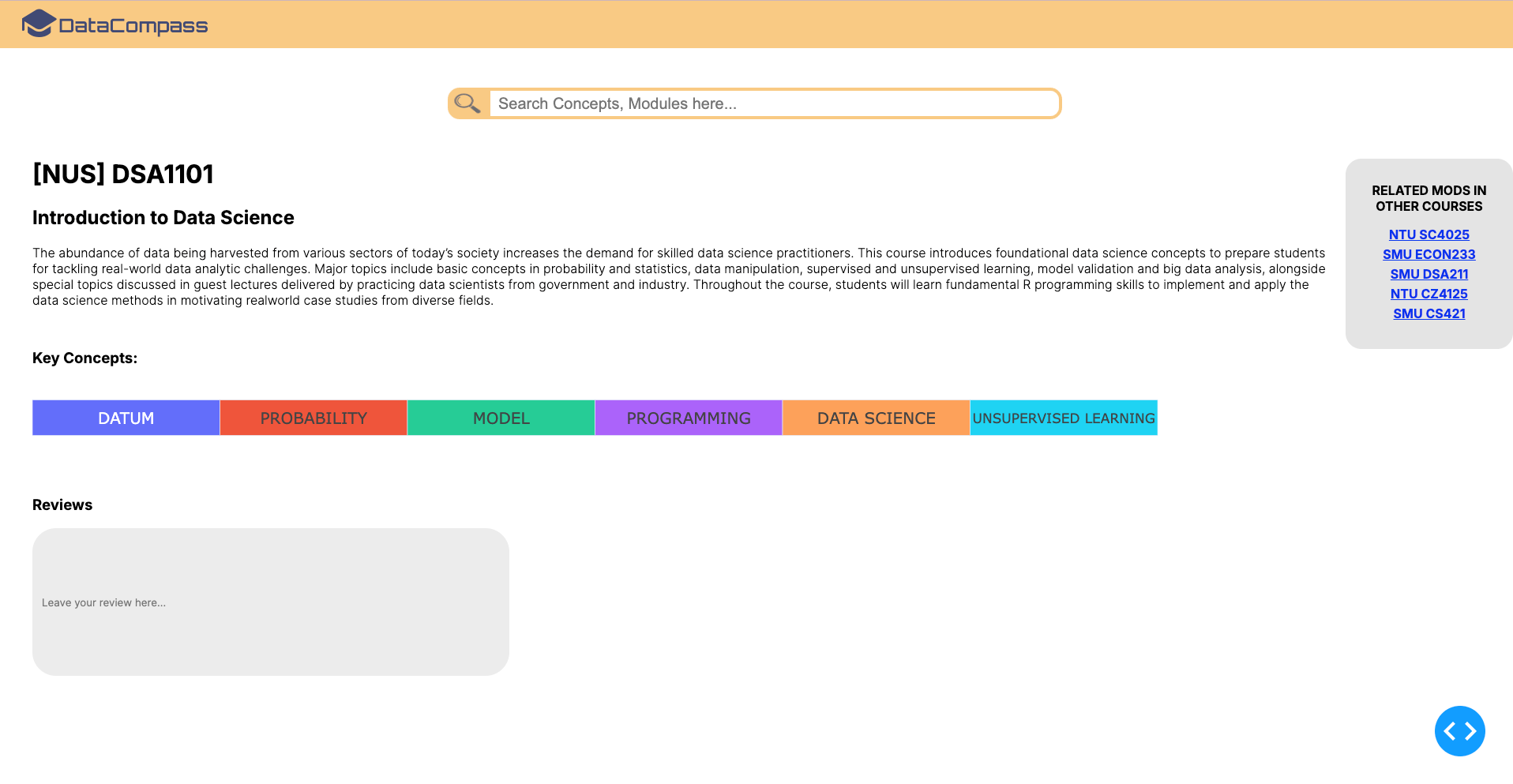
DataCompass
DataCompass is a website designed to assist incoming freshmen interested in Data Science in deciding which school can best accommodate their interests and career goals. This project primarily focuses on three leading institutions in Singapore: National University of Singapore (NUS), Nanyang Technological University (NTU), and Singapore Management University (SMU). DataCompass offers an in-depth guide to the unique courses, specialisations, and academic pathways available in Data Science at each of these schools, providing prospective students with a clear view of what each curriculum offers in terms of skills, competencies, and career opportunities.
As part of the backend team, my team collected and preprocessed data from the respective university websites via web scraping techniques, ensuring comprehensive course and programme information. To keep this data up-to-date, we implemented a CRON job to run the web scraping script every 6 months. Leveraging on machine learning, we applied sentiment analysis on course reviews and academic resources to provide an evaluation of course sentiment. We integrated all these components into a Flask backend to support our frontend team, enabling a cohesive user experience that delivers a data-driven comparison of the programmes offered at NUS, NTU, and SMU.
Python
NLP
Flask
Scikit-learn
Spacy
Requests
BeautifulSoup
Git
Docker

Time Series Analysis and Forecasting of Bitcoin Price
This project focuses on forecasting Bitcoin prices using a variety of Time Series analysis models, including Box-Jenkins Modelling (ARIMA, SARIMA), Smoothing Methods (Exponential Smoothing, Holt-Winters), and Regression Modelling techniques. The objective is to explore and apply different approaches to model and predict a highly volatile and dynamic market, like cryptocurrency.
Throughout this project, various data processing techniques were employed, such as data normalisation, differencing to achieve stationarity, and evaluating model performance using metrics like APSE (Average Percentage Squared Error). While the models did not yield perfect forecasting results, this project is a strong demonstration of applying classroom knowledge to solve real-world problems.
R
Forecast
Tseries
Stats

GovTech Projects
During my internship at GovTech, I was part of the Forward Deployed Team (FDT) supporting Workforce Singapore (WSG), where we collaborated closely with their Data Science team. I developed and deployed multiple frontend web applications using Streamlit on CStack, GovTech's cloud-native infrastructure platform. These applications were tailored to meet the needs of ID officers, allowing them to streamline their daily tasks. These applications included intuitive, user-friendly interfaces that simplified data access and task execution.
ASTAR Project
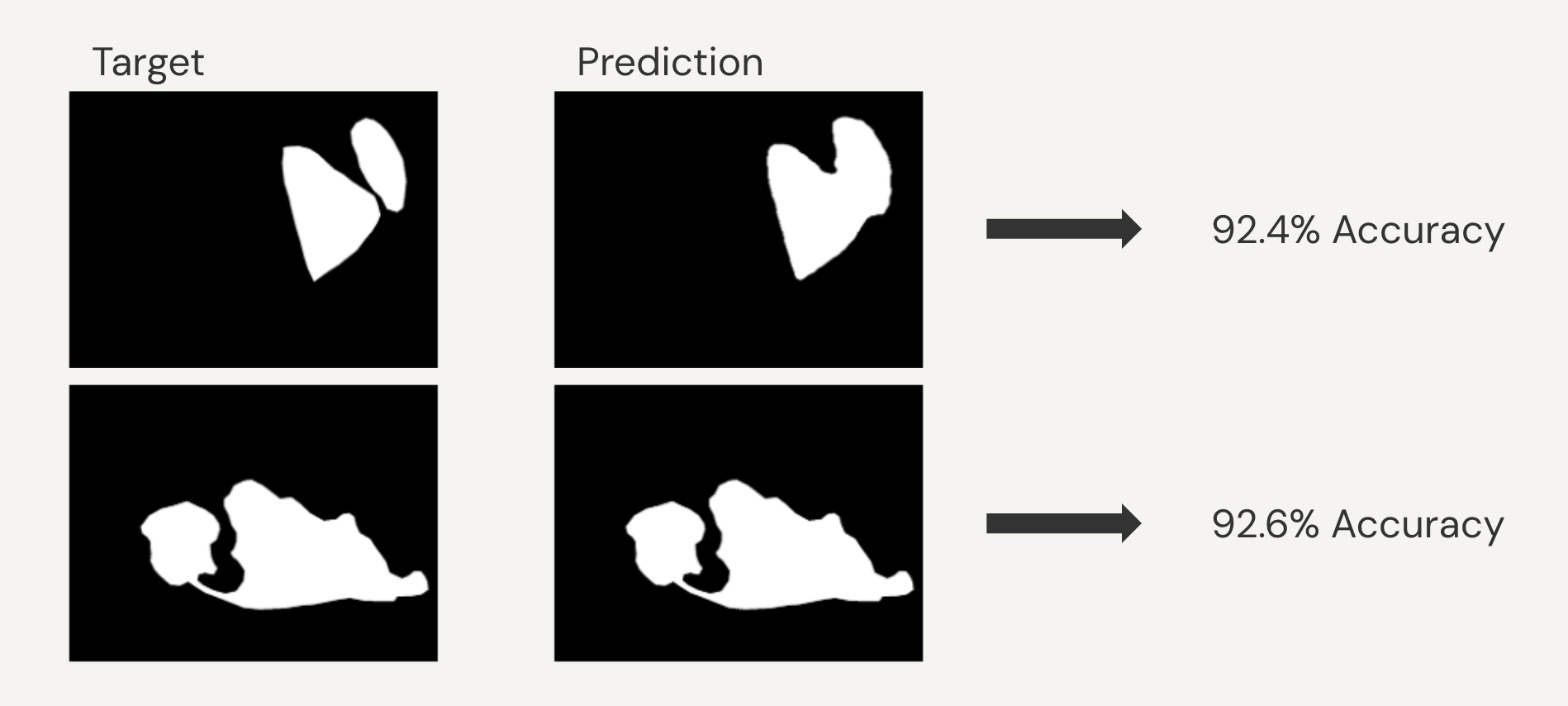
As part of my deep learning research internship, I collaborated with scientists on a project diagnosing eczema. I was responsible for detailed dataset annotated using LabelMe, followed by the implementation of a U-NET model for image segmentation. I optimised the model using Dice Loss to enhance diagnostic accuracy. The image above illustrates a sample output from the segmentation model, showcasing the model's capacity to isolate affected skin areas accurately.